As RF season 4 has been proposed, it’s time to bring this up again.
There is currently a bug with the calculation of Wearable Sets for rarity farming, when there are multiple sets to choose from. This is inconsistent and has actually varied across different RF seasons/rounds.
I discovered this while building the Rarity Farming pages on my site, because I only had the final rankings to work with, so had to retrospectively calculate their rarities at the time of the round snapshot. After doing this, my calculated rankings didn’t match up with the rewards that were actually distributed.
I posted about this back in March in the discord (aarchitects channel) and messaged coderdan, but naturally since the launch of the gotchiverse it’s been low priority ![]()
The core problem is that the wearable set and final rarity score displayed for your gotchi on its main page can be different to that used for the RF ranking.
This has mainly affected Sushi Chefs, Aagents, and also the Godlike/Apex sets - so it actually changed some top 10 rankings.
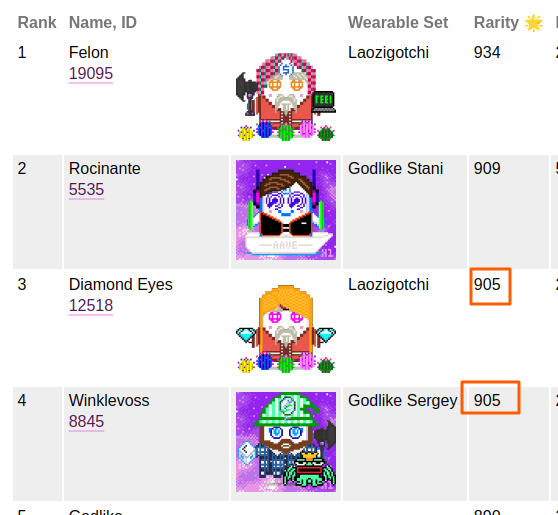
Here’s an example with Winklevoss (8845):


In the leaderboard, Winklevoss gets a suboptimal set assigned and is 906 rather than 907.
In Rarity Farming Season 2 round 4, this made him lose out on a tie, and should have been #3 not #4
You can see the different calculations for all of Seasons 2 and 3 on Aadventure.io - in “Advanced table config” check the option “(devs) Display alternate Rarity Scores for Wearable Set debugging”.
You’ll then see extra columns in the ranking table showing
- the actual RF ranking used for awarding prizes
- the data in the subgraph (which is usually very wrong)
- the ‘best’ score, which is also usually closest to what gets displayed on your gotchi page on the main site.

Some more examples:



Main findings:
-
The Rarity Farming Leaderboard, Aavegotchi website, and subgraph all use different approaches to find the equipped wearable set. This does have different results in some cases, including different final Rarity Score.
-
For the leaderboard, this affects Master Sushi Chefs and some Aagents, who are ranked lower (worse) than they should be. It also affects some high ranking gotchis where the Godlike set is picked over the better Apex set.
-
Important for community devs to know: the subgraph’s
equippedSetIDandwithSetsRarityScoreshould NOT be used: as well as the differences in calculations, it is also missing or out-of-date for many gotchis. -
(extra bug) The onchain wearable sets aren’t up-to-date with the latest fixes. The subgraph uses these, which is why it doesn’t detect the Long Distance Runner set correctly (water/wine mixup).
-
(extra bug) Sets with two of the same hand item (Gunslinger) are NOT being strictly checked anywhere. The code will pick the set even if the gotchi only has one hand item equipped.
Key actions needed:
- Define and publish the algorithm for picking the best wearable set. This needs to have multiple levels of tiebreaker, with a final fallback that is guaranteed to produce a consistent order. (E.g. it is not enough to say ‘order alphabetically’, because there are multiple sets that have the same name.)
- Implement this algorithm for Rarity Farming leaderboards
For example:
- highest total set bonus (BRS plus magnitude of NRG, AGG, SPK, BRN bonuses)
- highest number of wearables in the set
- index of when the set was added onchain (earliest wins)
Tiebreaker 1. is the most important one for the leaderboard. The current leaderboard code only looks at the set bonus BRS, which is why it doesn’t pick the best one.
2 and 3 are arbitrary, but are also important to define clearly, because different sets can tweak traits in different ways, which may be good or bad for the gotchi. This can affect the leaderboard when the trait is used for the tiebreaker. The important thing is to decide on an approach and be consistent, so that what the player sees as the current set (in both official and community-built websites) matches what’s used in the leaderboard. Right now the set-matching relies implicitly on ordering of sets and the way each algorithm is written.
Edit: for completeness, I guess I should mention the ‘historical’ leaderboards on the main site (available when you click on ‘Block’). That feature was added after my research back in March. They seem to be generated simply by querying the subgraph for a particular block and applying the current algorithm: unfortunately, as you will realise if you read the above, the actual algorithm for ranking as well as the wearable sets data has changed over time, so these generated leaderboards do not match reality ![]()
